Kapitel 4 — Entscheidungsbäume zur Regression (winequality-red)
Einleitung: Im Gegensatz zu Klassifikationsbäume, die verwendet werden, um eine Zielvariable zu kategorisieren, werden Regressionsbäume verwendet werden, um eine numerische Zielvariable vorherzusagen**.
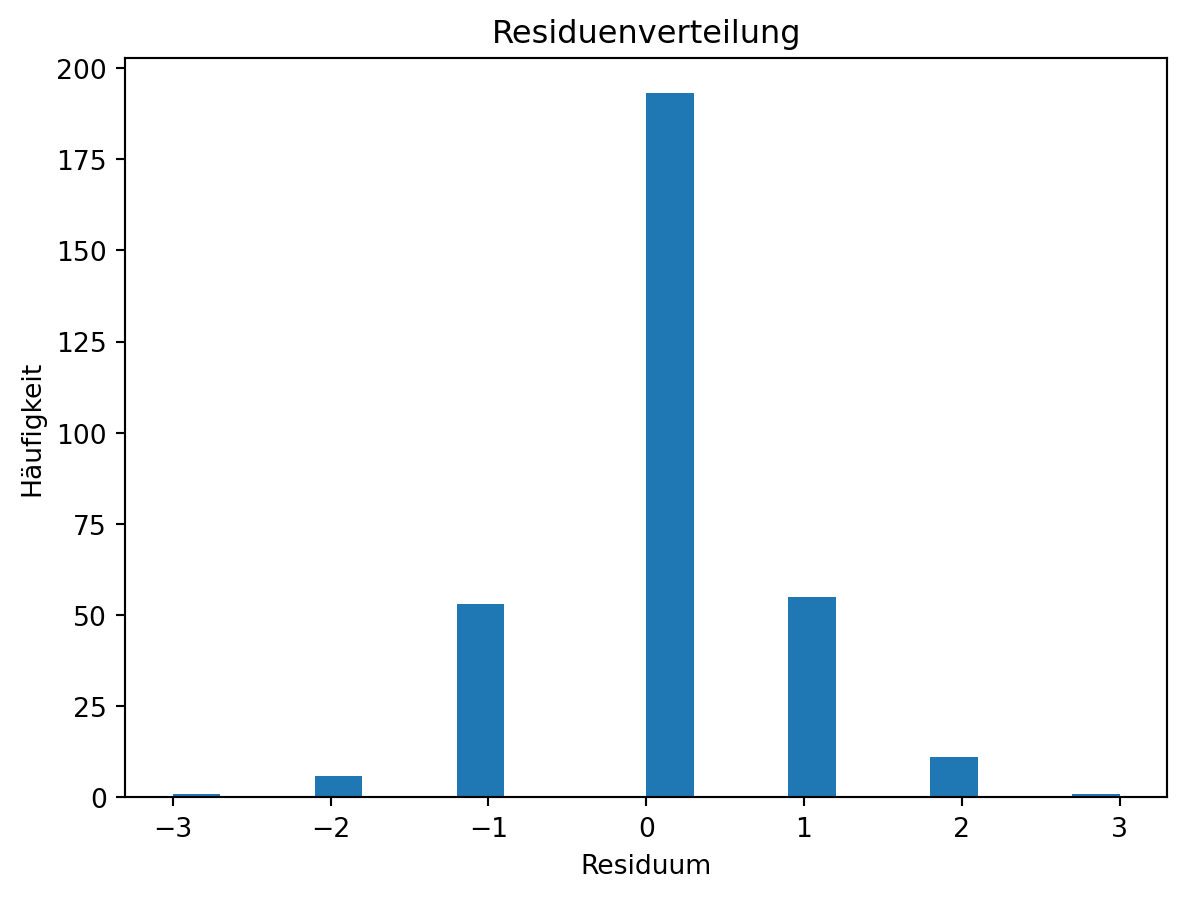
Ziel: Regressionsbaum mit scikit-learn für die Vorhersage der Weinqualität trainieren, evaluieren (MSE, RMSE, \(R^2\)), visualisieren und durch Hyperparametertuning verbessern
Aus dem UCI Machine Learning Repository wird der Datensatz winequailty-red für die Verprobung von Weinen verwendet. Der winequality-red Datenset ist Teil des UCI Machine Learning Repositories und enthält chemische Analyse von Weinen sowie die Qualitätseinschätzungen von Experten. Der Datensatz enthält 1599 Einträge und 12 Merkmale:
fixed acidity
volatile acidity
citric acid
residual sugar
chlorides
free sulfur dioxide
total sulfur dioxide
density
pH
sulphates
alcohol
Zielvariable:quality (ganzzahlig 0–10) -> Qualität des Weins, die auf einer Skala von 0 bis 10 bewertet wird
Legen Sie die CSV lokal ab und tragen den Pfad unten ein. Erwartete Spalten (Features):
# Passen Sie den Pfad an, falls nötigDATA_PATH ="../data/processed/winequality-red.csv"# z.B. ".../winequality-red.csv"ifnot os.path.exists(DATA_PATH):raiseFileNotFoundError(f"Datei nicht gefunden: {DATA_PATH}\n""Laden Sie 'winequality-red.csv' vom UCI Repository herunter und ""speichern Sie sie am angegebenen Ort." )# Ladendf = pd.read_csv(DATA_PATH, sep=";")# Schneller Datencheck (knapp gehalten)print(df.shape)print(df.isnull().sum().to_string())df.head(3)
Es gibt verschiedene Kriterien, die zur Messung der Qualität eines Splits verwendet werden können, z. B. der mittlere quadratische Fehler (MSE – Mean Squared Error), der mittlere absolute Fehler (MAE – Mean Absolute Error) usw.
Standardmäßig verwendet DecisionTreeRegressor das MSE-Kriterium (squared_error) für den Split, und keine Begrenzung für die Anzahl der Blattknoten oder die Tiefe des Baums. Das ist auch das am häufigsten verwendete Kriterium für Regressionsbäume allgemein. Dieser ist als Summe der quadratischen Unterschiede zwischen den vorhergesagten und den tatsächlichen Werten für jede Stichprobe in einer Teilmenge definiert:
$ MSE=_{i=1}^n(y_i - _i );, $
wobei \(n\) die Anyahl der Stichproben in der Teilmenge ist, \(y_i\) der tatsächliche Zielwert für die \(i\)-te Stichprobe ist, und \(\widehat{y}_i\) der vorhergesagte Zielwert für \(i\)-te Stichprobe ist.
Knoten-Impurität (Split-Kriterium) für einen Knoten \(S\):
Daten am aktuellen Knoten \(S\) nach Merkmal\(x_j\) und Schwelle\(v\) in zwei Teilmengen aufteilen \(S_L=\{\,i\in S: x_{ij}<v\,\}\), \(S_R=\{\,i\in S: x_{ij}\ge v\,\}\)
Für jede Teilmenge den MSE berechnen
Feature–Schwellenwert-Paar wählen, das den gewichteten Kind-MSE minimiert