Verarbeitung und Erzeugen von Daten
Motivation und Problemstellung
- reale Daten sind oft verrauscht, unvollständig oder inkonsistent
- Ziel: Datenqualität verbessern, damit ML-Algorithmen effektiv lernen
- typische Probleme: fehlende Werte, Ausreißer, falsches Format, Rauschen
- Merkmale (Features) = Eingabegrößen für das Modell
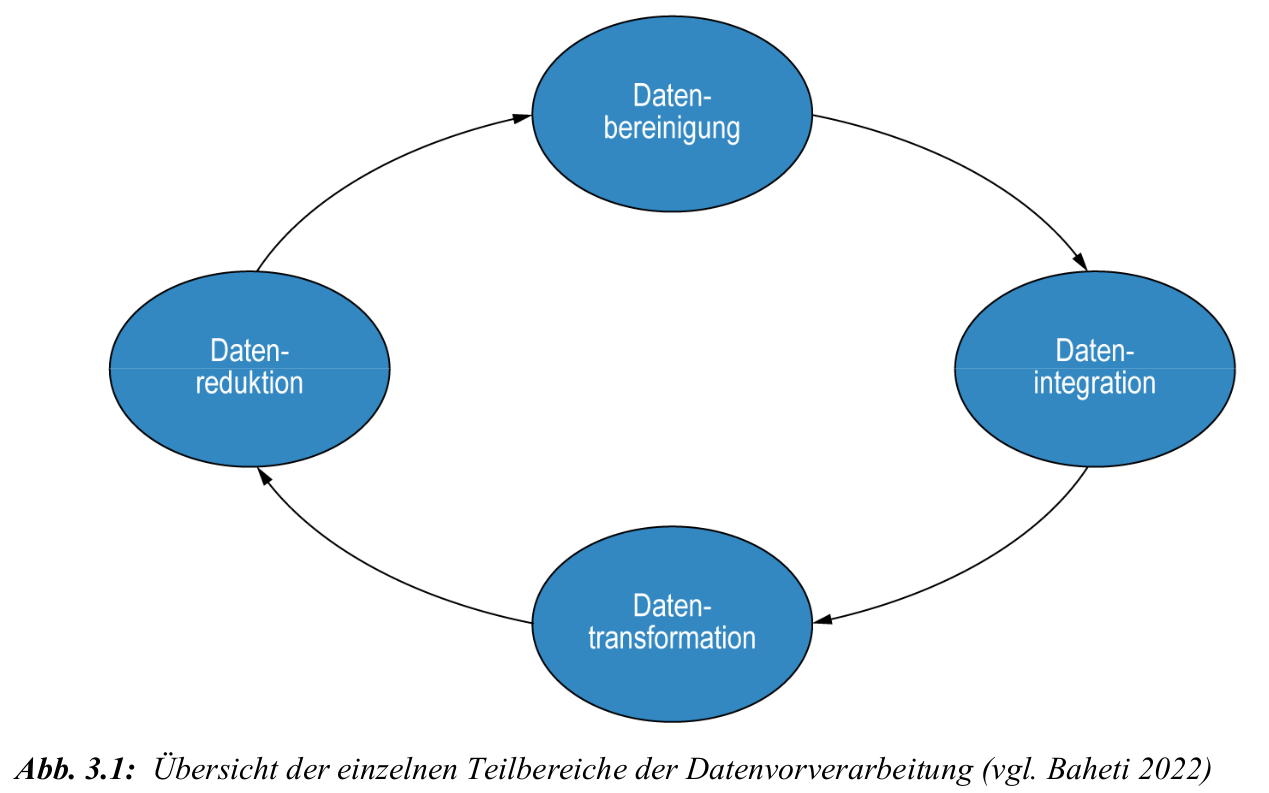
Datenbereinigung
- Ziel: Korrektur oder Entfernung fehlerhafter Einträge
- Methoden:
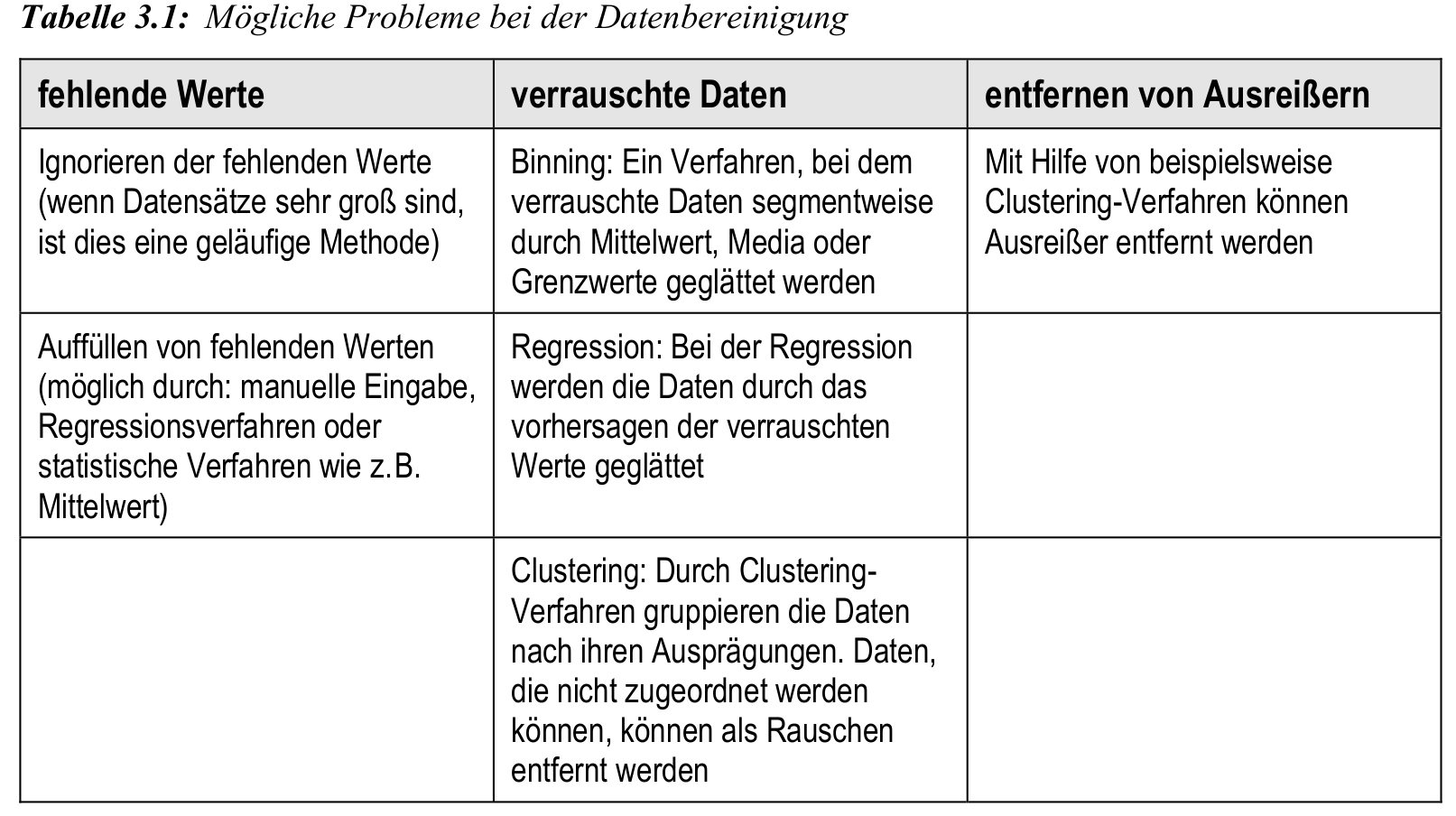
- fehlende Werte ignorieren oder durch Mittelwert, Regression o. Ä. ersetzen
- Rauschentfernung durch Binning, Regression oder Clustering
- Ausreißerbehandlung mittels Clustering oder Entfernung
Klausurrelevant: schonmal abgefragt (s. Altklausuren)
Datenreduktion
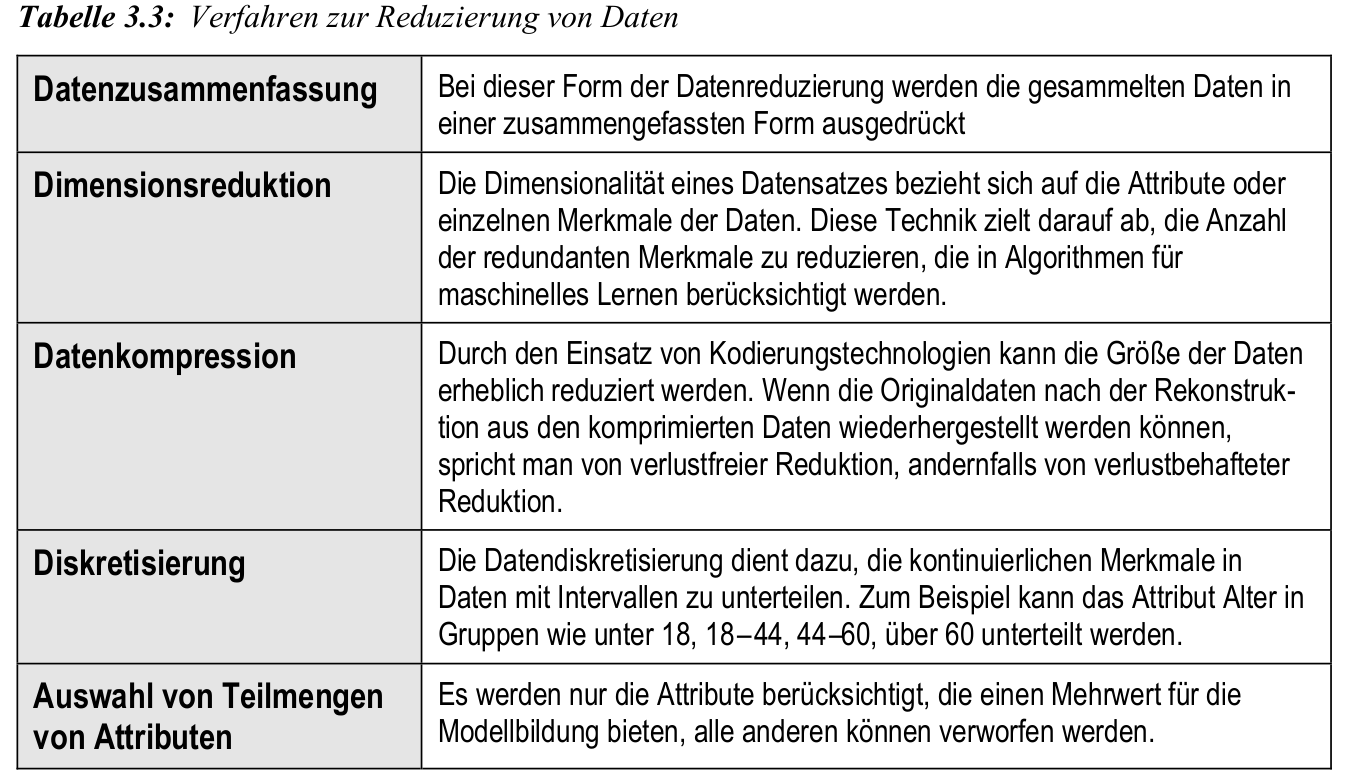
- Reduktion des Datenvolumens bei Erhalt der Analysequalität
- Verfahren: Datenkompression, Dimensionsreduktion, Diskretisierung
- Ziel: schnellere Verarbeitung bei geringem Informationsverlust
Klausurrelevant: schonmal abgefragt (s. Altklausuren)
Datenerweiterung: klassische Augmentation
Motivation und Prinzip
- Ziel: künstliche Vergrößerung von Trainingsdatensätzen
- hilfreich bei kleinen Datenbasen oder zur Erhöhung der Robustheit
- neue Datenpunkte entstehen durch gezielte Veränderungen bestehender Beispiele
- besonders verbreitet bei visuellen Daten
Datenerzeugung mit Deep Learning
GANs und neuronale Stilübertragung
- Generative Adversarial Networks (GAN):
- bestehen aus Generator und Diskriminator im Wettstreit
- erzeugen neue Datenpunkte, die echten Daten ähneln
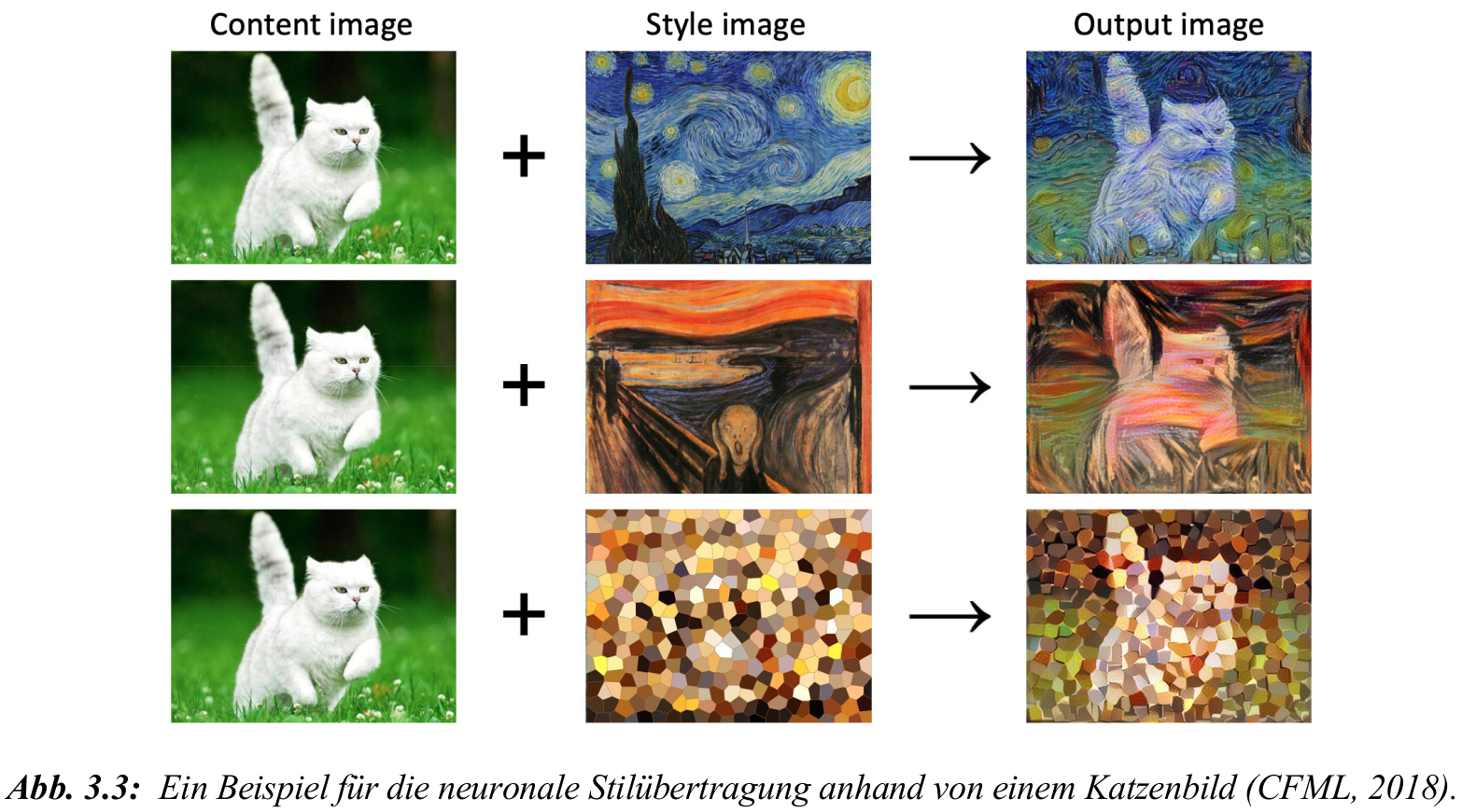
- Neuronale Stilübertragung:
- kombiniert Inhaltsbild und Stilbild zu synthetischem Output
- Output enthält die Inhalte des ersten Bilds im Stil des zweiten
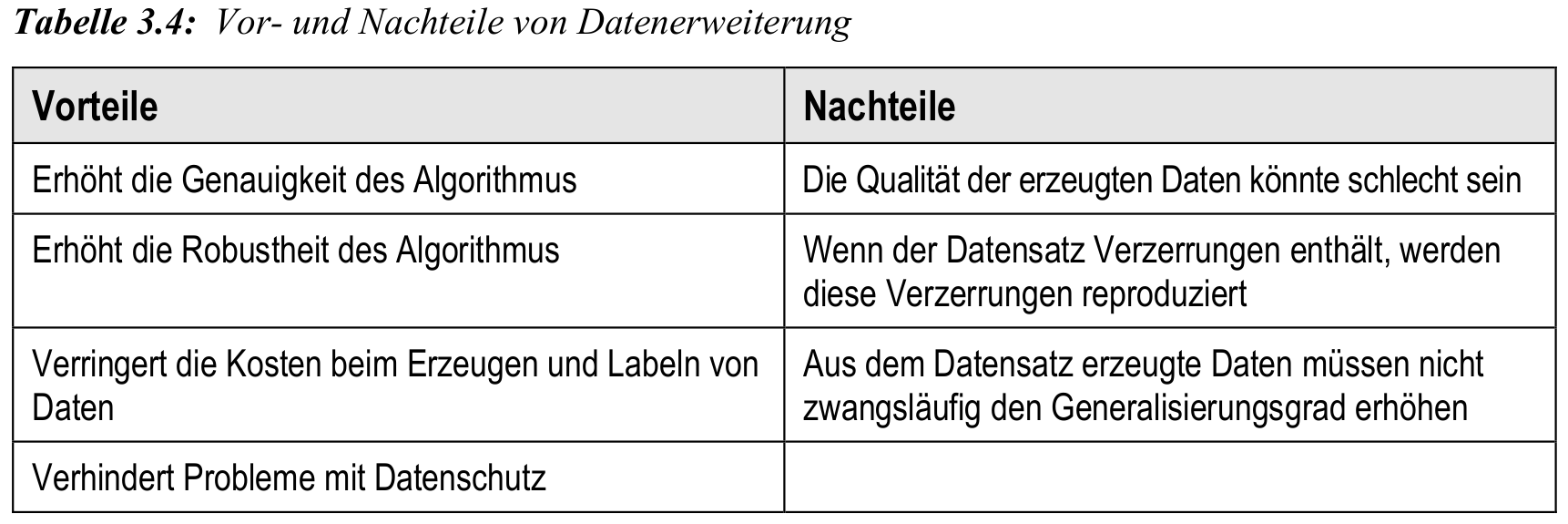
Datenerweiterung: Vor- und Nachteile
- Datenerweiterung kann Genauigkeit und Robustheit von KI verbessern
- sie ersetzt jedoch keine hochwertigen Originaldaten
- Risiken: Reproduktion von Verzerrungen, mangelhafte Qualität künstlicher Daten
- besonders kritisch bei ethischen oder sensiblen Anwendungen
Potentiell Klausurrelevant: aber noch nie abgefragt
Simulation als künstliche Datenquelle
Prinzip und Zielsetzung
- Simulation = virtuelle Nachbildung realer Prozesse auf Basis mathematischer Modelle
- Ziel: Erzeugung realistischer, aber kontrollierter Daten ohne physische Durchführung
- zentrale Bestandteile:
- Modell des Systems (z. B. physikalisch, ökonomisch, biologisch)
- Eingabeparameter, die Systemverhalten definieren
- Ausgabevariablen, die analysiert und als Trainingsdaten genutzt werden
Vorteile gegenüber realer Datenerhebung
- keine Risiken für Personen, Geräte oder Infrastruktur
- flexibel skalierbar, auch für seltene/extreme Szenarien
- vollständige Kontrolle über Ground Truth und Umweltvariablen
- geeignet bei Datenschutzproblemen oder nicht zugänglichen Szenarien
Anwendungsfelder
- Reinforcement Learning (RL):
- Training von Agenten via Trial & Error in sicherer Simulationsumgebung
- spätere Übertragung des Verhaltens in reale Systeme (z. B. Roboter)
- Forecasting (z. B. Energie, Logistik), Anomaliedetektion, Risikobewertung
- Simulation synthetischer Bilddaten (z. B. für medizinische Diagnostik)
Back to top
